
VERİ MADENCİLİĞİ NEDİR?
- yöntem istatistik

- 17 Tem 2020
- 2 dakikada okunur
Güncelleme tarihi: 9 May 2021
Veri madenciliğinin standart tanımından önce daha iyi kavrayabilmek için önce “madenci” kavramını ele alalım. Bir madenci yer altında saklı olan çeşitli yararları mineral ve cevherleri kazarak ortaya çıkaran kişidir. Veri madenciliği de tam olarak böyledir. Büyük ölçekteki verilerin içinde saklı kalan, ilk bakışta anlamlı olarak belirlenemeyen verilerin içinden faydalı bilgiler elde etme işidir. Bu nedenle veri madenciliği, verileri düzenli bir şekilde toplayıp gelişmiş analiz yöntemleri ile sorgulamalar yapmanın daha ötesinde bir boyuttur.
Veri madenciliği bir şirketin aylık cirosunu hesaplamak, ürünlerin hangi lokasyonda daha fazla satıldığını belirlemek, hangi müşterilerin sadık olup hangi müşterilerin devamlılık göstermediğini belirlemek değildir. Onlarca hatta yüzlerce değişkene sahip çok büyük verilerin doğru algoritmalar ile bilgi edinilmesi veri madenciliğidir. Mühendislik, finans, tıp, telekomünikasyon, sigortacılık, bankacılık gibi birçok alanda veri madenciliği kullanılabilir.
Günümüzde büyük ölçekteki verilerin daha çok kullanılması ile veri madenciliği oldukça popüler ve geleceğin mesleklerinden biri olarak görülmektedir. Bir veri madencisi teorik istatistik bilgileri ile analiz programları aracılığıyla algoritmalar kurup tahmin yapar.

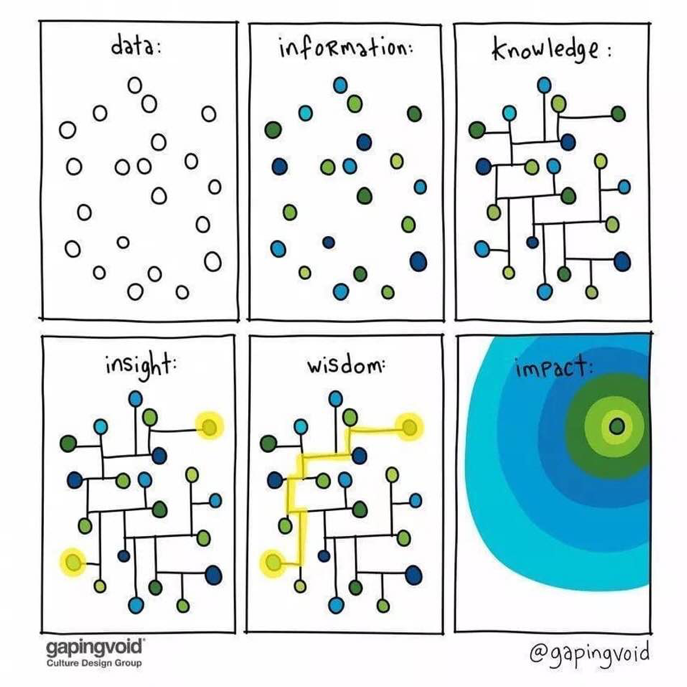
Veri Madenciliğinde Temel Kavramlar
Data (Veri): Herhangi bir sonuç çıkartılmamış ham veridir.
Information (Bilgi): Elde edilen ham verilerin işlenip bir anlama sahip olan veridir.
Knowledge (Bilgi): Anlam kazanıp zihinde bir yere oturtulan veridir.
Wisdom (Bilgelik): Zihindeki verinin bir eyleme dönüştürülmesi olarak açıklanabilir.
Ham veriden bilgelik sürecine doğru gidilen yolda bu dört kavram sırasıyla birbirini takip eder, geçmişten elde edilen bilgiler ile gelecek tahmin edilir.
İstatistik ve Veri Madenciliği
Hem istatistiğin hem de veri madenciliğinin anahtar kelimeleri veri ve bilgidir. Zaten veri madenciliğinde kullanılan algoritmalar aslında birer istatistiksel yöntemdir. İstatistiğin amacı kitle hakkında edinilen bilgiler doğrultusunda tahmin yapmaktır, veri madenciliğinde ki amaç ise edinilen bilgilerden harekete geçirecek kararlar alınmasını sağlamaktır.
Veri Madenciliğinde Kullanılan Modeller
Veri madenciliğinde tahmin edici modellerin yanında tanımlayıcı modellerde kullanılır. Örneğin bir şirketin bir sonra ki ay hangi müşterinin kendilerini ile çalışmayacağını tahmin etmek ya da bir sigorta şirketinin işlemde sahtekârlık olup olmadığı tahmin edici modellerdin. Tanımlayıcı modeller ise, hangi ürünler birlikte daha çok satıldığını belirlemek ya da hangi müşterilerin alışveriş tutumlarının benzer olduğunu belirleyen modellerdir. Bu amaçla geçmişten günümüze geliştirilmiş birçok model vardır.
Karar Ağaçları: Veri setindeki karmaşık yapıyı karar verilebilecek basit bir yapıya çevirir. Kolay yorumlanması ve güçlü tahminlerde bulunduğu için sık kullanılan bir modeldir. Genellikle CART, C5.0, CHAID ve Quest algoritmaları kullanılır.
Bayes Ağları: Bayes ağının temeli olasılığa dayanır. Bir sınıflandır probleminde değişkenlerin alt kümeleri arasındaki koşullu bağımsızlıklarını tanımlamak için değişkenlere ait koşullu olasılık dağılımlarını kullanır.
Yapay Sinir Ağları: İnsan beyninden esinlenilerek ortaya çıkmıştır. YSA, veriler arasındaki ilişkiyi ortaya çıkarmayı sağlayan, sınıflandırma ve regresyon problemlerinde kullanılabilen kuvvetli bir algoritmadır.
K-En Yakın Komşu: Güçlü bir sınıflandırma algoritmasıdır. Bu algoritma sınıflar belli olan bir kümeye, eklenecek yeni gözlemin hangi sınıfa ait olduğunu belirlemeye yarar. Gözlemlerin birbirine olan uzaklıkları hesaplanarak yeni gözleme en yakın olan komşular belirlenir.
Birliktelik Analizi: Satın alımlarda eğilimlerin nasıl olduğunu belirlemede yarayan, müşteriye daha fazla ürün satılmasını sağlayan bir analiz biçimidir. Birliktelik kurallarının yanında ardışık zaman örüntüleri ile yapılan işlemlere zaman faktörü de eklenerek analiz güçlendirilebilir. Daha çok Apriori algoritması bu alanda tercih edilir.
Destek Vektör Makinesi: Amacı veri setini birbirinden en küçük hata ile ayıran en uygun doğruyu ya da eğriyi belirlemektir. Bu şekilde veri setini istenilen sınıf sayısına bölerek sınıflandırma yapılabilir.
Kümeleme: Bir veri kümesinin ayırılmak istenilen grup sayısı kadar merkezi belirlenerek her gözlemin bu merkezleri olan uzaklıkları hesaplanır. Çıkan sonuca göre tüm gözlemler kendilerine en yakın olan kümeye atanarak veri seti sınıflandırılmış olur. K-means, Kohonen Ağlar ve Two-Step algoritmaları kümeleme tekniğinde kullanılan algoritmalardır.


Yorumlar